Azure Cosmos DB Is the Agent Memory Bet
The Real Enterprise Value of Agentic Coding with Azure Cosmos DB
The smartest agent demo is usually the least enterprise-ready. The real production differentiator is not model cleverness; it is whether your agent can remember, recover, and coordinate under failure.
That is why Azure Cosmos DB matters in agentic coding.
Not because it makes agents smarter. It does not. Because it gives long-running agent systems a durable operational memory and state layer.
Last quarter, a 14-person internal platform team at a regulated manufacturer showed me an agent workflow that looked great in a demo until a human approval sat idle for 19 hours and the execution path had to be reconstructed from logs, blob files, and one developer’s local notebook.
Why agentic coding suddenly needs a real state layer
The market has moved past “ask a model a question” and into implemented workflows: retries, tool calls, approvals, handoffs, resumability, and sessions that live longer than a single HTTP request.
That changes the architecture.
The hard problem is no longer model access. Azure OpenAI, orchestration frameworks, and hosted agent services have made model invocation relatively straightforward. The hard problem is operational memory:
- Where does the conversation thread live?
- Where do tool outputs get persisted?
- How do you checkpoint a workflow before a long-running action?
- How do you resume after a timeout, duplicate delivery, or human delay?
- How do multiple agents share state without becoming tightly coupled?
This is exactly why Azure Cosmos DB for NoSQL is relevant in Microsoft-first architectures. Microsoft explicitly integrates Azure Cosmos DB for NoSQL with Foundry Agent Service through a data connector for thread storage and management of agent conversations and histories, which is a strong signal that persistent conversational state is becoming a standard production pattern, not an optional add-on.
If you are still evaluating agent platforms as if the main question is “Which model is best?”, you are solving the wrong enterprise problem.
The real job of Cosmos DB in an agentic system
Cosmos DB is not your model layer. It is not your reporting warehouse. It is not your cheap archive. Its real job is operational state:
- conversation state
- tool outputs
- intermediate plans
- workflow checkpoints
- event history
- user and tenant context
- coordination records between agents
- dedupe keys for idempotency
- resumability metadata
This is where document-oriented storage fits naturally. Agent state is semi-structured, changes shape over time, and often needs low-latency reads and writes under unpredictable execution paths. Forcing that too early into a rigid relational schema usually creates friction rather than discipline.
A useful mental model is this:
- Azure OpenAI or an orchestration service decides what to do next.
- Cosmos DB remembers what has already happened.
- The combination is what makes the system survivable.
Here is a simple way to think about the state model and partitioning choices for conversations, tool outputs, and workflow checkpoints.
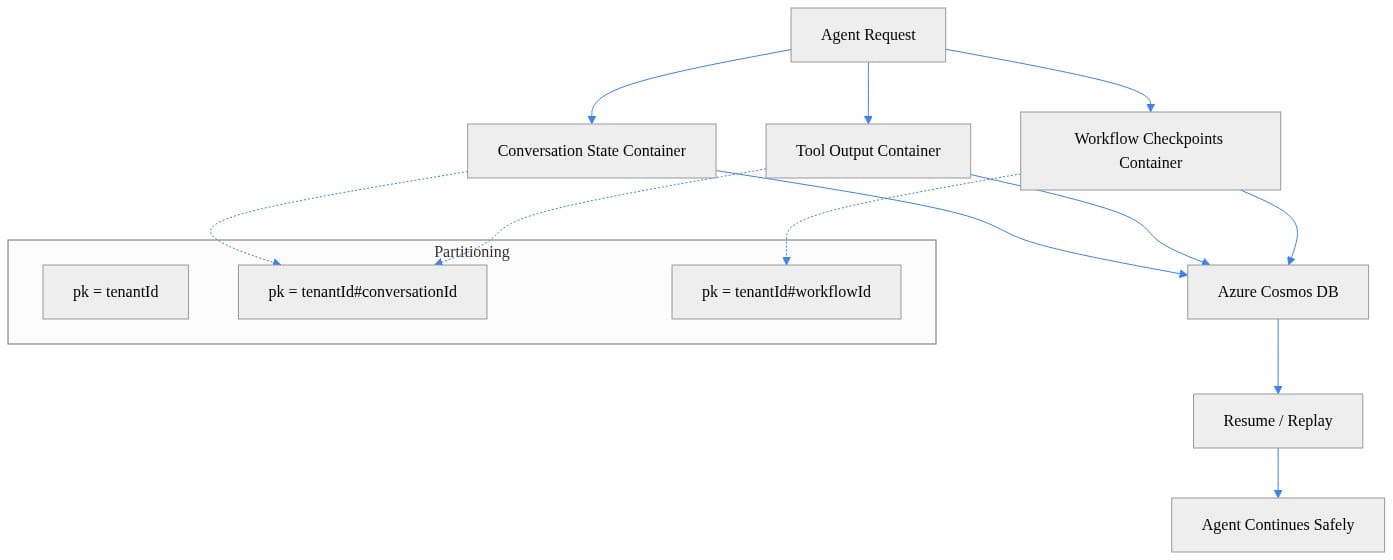
What to notice: the partition key is not an implementation detail. It is the architecture. If you get it wrong, your cost, latency, and recovery behavior all degrade at once.
Where Cosmos DB creates enterprise value, and where it does not
This is the opinionated part: Cosmos DB is valuable when you need low-latency, globally available, elastic operational state. It is not a universal answer.
Cosmos DB vs Azure SQL
Choose Azure SQL when the center of gravity is strongly relational transactions, fixed schemas, and SQL-centric operational reporting.
Choose Cosmos DB when the center of gravity is high-velocity, semi-structured agent state: session memory, tool traces, checkpoints, and globally distributed operational data.
Coexistence pattern: keep systems of record in SQL, and persist agent runtime state in Cosmos DB.
Cosmos DB vs Azure AI Search
Choose Azure AI Search when the problem is indexing, ranking, retrieval quality, and corpus navigation.
Choose Cosmos DB when the problem is live application state and transactional memory.
Coexistence pattern: Search finds grounding content; Cosmos DB stores what the agent did with it.
Cosmos DB vs Azure Storage
Choose Azure Storage when you need cheap blobs, transcripts, large artifacts, exports, and archives.
Choose Cosmos DB when you need queryable, low-latency state that drives workflow decisions.
Coexistence pattern: store large artifacts in Storage and keep references plus workflow metadata in Cosmos DB.
If your workload is mostly archival, BI-heavy, or deeply relational, Cosmos DB should not lead. Enterprise value comes from fit, not from putting every byte into the same service.
A hands-on pattern: build the memory backbone first
If you are designing an agentic application on Azure, start by modeling the state backbone before you tune prompts.
A practical baseline is three containers:
conversationsfor thread history and system/user/assistant messagestoolOutputsfor external action results and dedupe metadatacheckpointsfor resumability and workflow progress
These examples are illustrative baseline patterns; production implementations should tune indexing, retention, and concurrency controls to actual workload behavior.
# Python: Define Cosmos DB containers and document shapes for agent state, tool outputs, and checkpoints.
from azure.cosmos import CosmosClient, PartitionKey
endpoint = "https://example.documents.azure.com:443/"
key = "REPLACE_WITH_KEY"
client = CosmosClient(endpoint, credential=key)
db = client.create_database_if_not_exists(id="agentdb")
db.create_container_if_not_exists(id="conversations", partition_key=PartitionKey(path="/pk"), default_ttl=604800)
db.create_container_if_not_exists(id="toolOutputs", partition_key=PartitionKey(path="/pk"), default_ttl=259200)
db.create_container_if_not_exists(id="checkpoints", partition_key=PartitionKey(path="/pk"), default_ttl=-1)
conversation_doc = {"id": "msg-001", "pk": "tenantA#conv42", "tenantId": "tenantA", "conversationId": "conv42", "role": "user", "content": "Summarize QBR notes", "ttl": 604800}
tool_output_doc = {"id": "tool-001", "pk": "tenantA#conv42", "toolName": "search", "inputHash": "sha256:abc", "result": {"hits": 3}, "ttl": 259200}
checkpoint_doc = {"id": "wf-42#step-2", "pk": "tenantA#wf-42", "workflowId": "wf-42", "step": 2, "status": "completed", "resumeToken": "next:3"}
What to notice: the TTL choices encode policy. Conversation turns and tool outputs often deserve bounded retention, while checkpoints may need to remain until explicit cleanup.
Once the containers exist, the next discipline is partition-aware access. Agents are chatty. If you make every read a fan-out query, you will pay for it in both RU consumption and latency.
# Python: CRUD flow for writing and reading conversation state with partition-aware access.
from azure.cosmos import CosmosClient, exceptions
client = CosmosClient("https://example.documents.azure.com:443/", credential="REPLACE_WITH_KEY")
container = client.get_database_client("agentdb").get_container_client("conversations")
pk = "tenantA#conv42"
item = {"id": "msg-002", "pk": pk, "role": "assistant", "content": "Here is the summary.", "sequence": 2}
container.upsert_item(item)
read_back = container.read_item(item="msg-002", partition_key=pk)
read_back["content"] = "Here is the revised summary."
container.replace_item(item=read_back["id"], body=read_back)
query = "SELECT * FROM c WHERE c.pk = @pk ORDER BY c.sequence"
params = [{"name": "@pk", "value": pk}]
messages = list(container.query_items(query=query, parameters=params, partition_key=pk))
print([m["content"] for m in messages])
container.delete_item(item="msg-002", partition_key=pk)
What to notice: the query is scoped to a single partition key. That is what predictable low latency looks like in practice, and it is also how you avoid unnecessary query cost.
Production patterns that actually justify Cosmos DB
I would justify Cosmos DB in an enterprise agent system for five patterns.
1. Durable conversation threads
This is the most obvious one, and Microsoft’s Foundry Agent Service connector support makes it concrete. If your agents need thread storage and history management, Cosmos DB is a natural persistence layer.
2. Checkpoint-and-resume for long-running workflows
This is the pattern that separates demos from systems. Long-running agents should be modeled as recoverable workflows with explicit state transitions.
Here is a simple idempotent checkpoint pattern using a dedupe key.
# Python: Idempotent checkpoint-and-resume using dedupe keys to prevent duplicate step execution.
from azure.cosmos import CosmosClient, exceptions
client = CosmosClient("https://example.documents.azure.com:443/", credential="REPLACE_WITH_KEY")
container = client.get_database_client("agentdb").get_container_client("checkpoints")
tenant_id, workflow_id, step = "tenantA", "wf-42", 3
pk = f"{tenant_id}#{workflow_id}"
dedupe_id = f"{workflow_id}#step-{step}#tool-search#sha256:abc123"
checkpoint = {"id": dedupe_id, "pk": pk, "workflowId": workflow_id, "step": step, "status": "started"}
try:
container.create_item(checkpoint)
print("First execution: proceed with work")
except exceptions.CosmosResourceExistsError:
existing = container.read_item(item=dedupe_id, partition_key=pk)
print(f"Duplicate detected: status={existing['status']}")
What to notice: duplicate execution is handled as a normal operational case, not as an exception the architecture hopes never happens.
And here is the companion pattern for resuming from the latest successful checkpoint.
# Python: Resume a long-running workflow from the latest completed checkpoint.
from azure.cosmos import CosmosClient
client = CosmosClient("https://example.documents.azure.com:443/", credential="REPLACE_WITH_KEY")
container = client.get_database_client("agentdb").get_container_client("checkpoints")
pk = "tenantA#wf-42"
query = """
SELECT TOP 1 c.step, c.resumeToken
FROM c WHERE c.pk = @pk AND c.status = 'completed'
ORDER BY c.step DESC
"""
params = [{"name": "@pk", "value": pk}]
latest = list(container.query_items(query=query, parameters=params, partition_key=pk))
next_step = 1 if not latest else latest[0]["step"] + 1
resume_token = None if not latest else latest[0]["resumeToken"]
print({"next_step": next_step, "resume_token": resume_token})
What to notice: recovery starts from persisted state, not from re-running the entire workflow or scraping logs. If multiple workers may touch the same workflow state, add optimistic concurrency with ETags so one worker does not silently overwrite another’s checkpoint.
3. Event history for auditability and replay
If you operate in regulated environments, you need more than “the agent said it did X.” You need event history that supports replay, incident analysis, and traceability.
4. Shared coordination fabric for multi-agent systems
Planner, retriever, and executor agents should not be tightly coupled through in-memory assumptions. Shared durable state gives them a coordination fabric without forcing direct dependency chains.
5. Operational memory plus retrieval metadata
Many enterprise systems need both:
- retrieved context from a corpus
- live execution state from the current workflow
Those are different data problems, but they often meet in the application layer.
The trade-offs architects cannot ignore
Cosmos DB is powerful, but it is unforgiving of lazy design.
Partitioning is the first decision
Your candidate partition keys are usually some variation of:
tenantIdtenantId#conversationIdtenantId#workflowIdagentInstanceId
Each choice changes hot partition risk, cross-session query behavior, tenancy isolation, replay efficiency, and RU consumption.
For conversation history, tenantId#conversationId is often a strong default because reads and writes stay localized. For checkpoints, tenantId#workflowId is usually more appropriate.
Consistency is a business decision
Session consistency is often enough for agent memory because a workflow commonly needs read-your-writes semantics for the same session or client interaction.
But stronger consistency may be justified for approvals, handoffs, or financially sensitive actions where stale reads create business risk.
Cost comes from behavior, not just scale
Agent loops can be extremely chatty. Cost is shaped by:
- write amplification
- indexing policy
- retention duration
- cross-partition queries
- verbose event logging
- duplicate tool traces
You control a lot of this through selective indexing, TTL, and event compaction.

Governance and security are the real attack surface
The industry talks too much about jailbreaks and not enough about memory abuse.
The bigger enterprise risks are often in the state layer:
- over-broad access to conversation history
- cross-tenant leakage
- poisoned tool outputs being reused as trusted memory
- replay of stale checkpoints
- excessive retention of sensitive traces
This is why identity boundaries matter. Users, agents, tools, and data stores should not share broad credentials. Managed identities and least-privilege data-plane access should be the baseline.
This example shows the shape of using managed identity from an Azure-hosted service to access Cosmos DB.
# Python: Use managed identity with Cosmos DB in Azure-hosted agent services.
from azure.identity import DefaultAzureCredential
from azure.cosmos import CosmosClient
endpoint = "https://cosmosagentdemo1234.documents.azure.com:443/"
credential = DefaultAzureCredential()
client = CosmosClient(endpoint, credential=credential)
container = client.get_database_client("agentdb").get_container_client("conversations")
item = {"id": "msg-100", "pk": "tenantA#conv99", "role": "system", "content": "Managed identity access works"}
container.upsert_item(item)
print(container.read_item(item="msg-100", partition_key="tenantA#conv99")["content"])
What to notice: the application does not need embedded secrets to read and write operational memory. But identity alone is not sufficient; the managed identity still needs the right Azure AD/RBAC or Cosmos DB data-plane permissions configured.
Why agentic coding matters beyond runtime architecture
There is another layer here that people underestimate: agentic coding itself.
The value of agentic coding with Cosmos DB is not that a coding assistant can generate a CRUD snippet. Any decent assistant can do that. The real value is when it encodes platform best practices into implementation choices:
- better partitioning defaults
- safer query patterns
- explicit TTL usage
- idempotent checkpoint design
- managed identity over secrets
- fewer accidental fan-out queries
- more consistent data access patterns across teams
That is why the Azure Cosmos DB Agent Kit is interesting. It signals that Microsoft sees the opportunity not just in runtime storage, but in improving implementation quality and reducing architecture drift across teams building AI applications.
For principal engineers and platform teams, that matters more than autocomplete. The real force multiplier is consistency.
My bottom line
The real enterprise value of agentic coding with Azure Cosmos DB is disciplined state.
Cosmos DB earns its place when your AI application must:
- remember across sessions
- coordinate across agents
- recover after failures
- operate globally with low-latency state access
- enforce retention and security boundaries on operational memory
It does not replace relational systems of record. It does not replace search. It does not replace blob storage. It becomes the durable state backbone between them.
That is the architecture I would recommend in a pragmatic Microsoft-first stack:
- agent orchestration in Azure’s agent platform
- Cosmos DB for operational memory and checkpoints
- Azure AI Search for corpus retrieval
- Azure Storage for artifacts and archives
- Azure SQL where relational systems of record still belong
One caution: Microsoft’s Agentic Retrieval Toolkit for Azure Cosmos DB is preview-only, so validate SLA and production support requirements before adopting it in a critical path. And for BI-heavy workloads or strongly relational operational cores, Cosmos DB is usually the wrong lead choice.
If you are evaluating Cosmos DB for agentic systems, do not ask whether it makes the demo cooler. Ask whether it makes failure survivable.
Which trade-off would you reverse: putting agent state in Cosmos DB instead of SQL, Search, or Storage first? And which failure mode forced you to rethink state design in the first place?
#CosmosDB #EnterpriseAI #DataArchitecture
Sources & References
- Integration with Foundry Agent Service - Azure Cosmos DB for NoSQL
- Unified AI Database - Azure Cosmos DB
- Distribute Data Globally - Azure Cosmos DB
- AI Agents and Solutions - Azure Cosmos DB
- Why build AI apps with Azure Cosmos DB? - Azure Cosmos DB for NoSQL
- Retrieval Augmented Generation - Azure Cosmos DB
- Azure Cosmos DB Agent Kit - Azure Cosmos DB for NoSQL
- Scaling Agentic Applications
- Agentic Retrieval Toolkit (Preview) - Azure Cosmos DB for NoSQL
- Cosmos DB Overview - Cosmos DB (in Azure and Fabric)
Try it yourself
Run this tutorial as a Jupyter notebook: Download runbook.ipynb (21 cells, 19 KB).



