Fabric Data Protection Decides Who Survives AI Scale
Using Fabric Data Protection to Make Your Data AI-Ready

AI readiness is a data protection problem, not a model problem. Most AI programs do not fail on model quality first; they fail when sensitive data is overshared, ownership is unclear, and governance arrives after Copilot and data agents are already in motion.
That is the uncomfortable truth in Microsoft Fabric estates.
My opinion: if you are running Fabric first, AI readiness is fundamentally an architecture decision about protection. Classification, labeling, access control, and processing standards are not compliance extras. They are the controls that determine whether downstream Copilot, data agents, retrieval, and analytics experiences are trustworthy, scalable, and safe.
Microsoft’s own platform positioning points in this direction. Fabric is presented as an AI-powered SaaS platform for end-to-end analytics, designed to improve consistency and accessibility at enterprise scale. That is exactly why protection matters more, not less: consistency without control simply scales mistakes faster (Microsoft Learn, IDEAS journey to a modern data platform with Fabric).
The real AI bottleneck is not model choice
The market still talks about AI adoption as if the biggest decision is model selection. It is not.
Executive teams routinely overestimate the risk of choosing the wrong model and underestimate the risk of exposing the wrong data. Once you introduce Fabric, Copilot, and conversational analytics into a shared analytics estate, every weak permission, unlabeled dataset, and ambiguous owner becomes an AI problem.
The old modernization question was, “Have we centralized the data?” The current question is, “Have we protected it well enough to let AI use it safely?”
Cloud Adoption Framework guidance is explicit that data for AI and analytics should be trusted, reusable, and secure by default, with Fabric enabling trusted data products (Microsoft Learn, Data for AI and Analytics - Guidance to set your organization's data strategy for AI and analytics). Those are operating requirements if you want AI systems to answer questions over enterprise data without creating new risk.
A specific example from the field: in Q4, a 14-person analytics team at a regulated lender had a Fabric proof of concept with semantic models and self-service reporting moving quickly, but the first executive demo stopped cold when a broadly shared workspace exposed HR-adjacent metrics to users who should never have seen them.
The model was not the issue. The protection design was.
Why Fabric-first estates raise the stakes
Fabric changes the blast radius of bad governance because it unifies experiences across OneLake, warehouses, lakehouses, Power BI semantic models, and AI-facing workflows. That unification is a major strength. It is also why protection decisions made early become inherited assumptions elsewhere.
Microsoft’s modernization story for Fabric is built around integrated analytics and better data consistency and accessibility across the enterprise (Microsoft Learn, IDEAS journey to a modern data platform with Fabric). The Cloud Adoption Framework complements that by recommending organizationwide data processing standards that define what enters OneLake, how teams refine it, and how it is published for analytics and AI (Microsoft Learn, Data Processing Standards for AI and Analytics).
A simple way to think about it:
- OneLake increases discoverability.
- Semantic layers increase usability.
- Copilot and data agents increase accessibility through natural language.
- Each benefit magnifies the cost of unclear ownership and inconsistent policy.
If you do not standardize ingestion, refinement, and publication rules, you do not have a stable AI foundation. You have a collection of assets that happen to be reachable by AI features.
Put classification, labeling, and access on the critical path
If you want broad AI activation, classification, sensitivity labeling, and access control belong on the critical path before rollout, not after.
These controls directly affect three things leaders say they want from enterprise AI:
- Lower oversharing risk
- Better retrieval quality
- Higher trust in AI-generated answers
If a lakehouse, warehouse, or semantic model has no clear owner, no classification, and no sensitivity context, you are asking AI to operate over data products that the business itself has not finished defining.
A practical pattern is to introduce a lightweight AI-readiness gate for Fabric assets. This is not production code; it is a pseudodata governance pattern for checking whether the basics are in place before AI activation.
# Lightweight governance audit: inventory assets and flag missing metadata before AI activation
assets = [
{"name": "SalesLakehouse", "type": "Lakehouse", "owner": "alex@contoso.com", "classification": "Confidential", "sensitivity": "High"},
{"name": "HRWarehouse", "type": "Warehouse", "owner": "", "classification": "Restricted", "sensitivity": "High"},
{"name": "MarketingModel", "type": "SemanticModel", "owner": "mia@contoso.com", "classification": "", "sensitivity": "Medium"},
]
required = ("owner", "classification", "sensitivity")
for asset in assets:
missing = [field for field in required if not str(asset.get(field, "")).strip()]
status = "AI_READY" if not missing else "BLOCKED"
print({
"asset": asset["name"],
"type": asset["type"],
"status": status,
"missing": missing
})
The point is simple: if an asset is missing owner, classification, or sensitivity metadata, it should not quietly flow into downstream AI experiences as if it were ready.
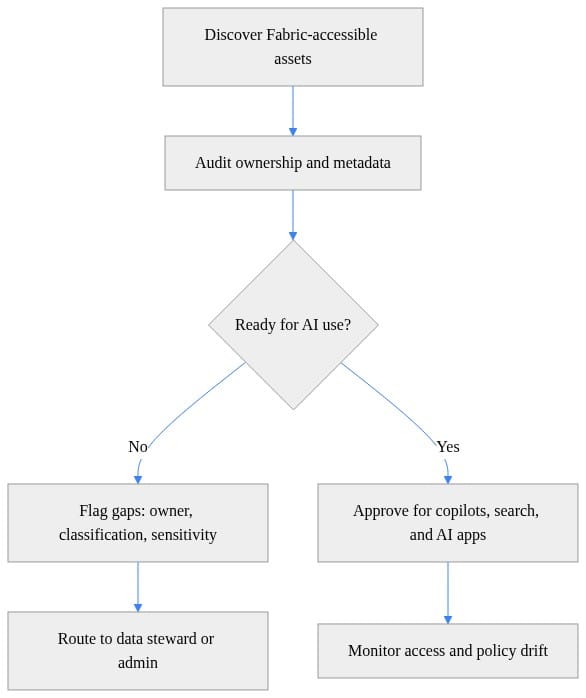
Treat this as a control loop: discover assets, audit metadata, route gaps to stewards, and approve only governed assets for copilots, search, and AI applications.
What breaks when governance is retrofitted later
Retrofitted governance fails in predictable ways.
First, sensitive data leaks into AI responses, not because the AI broke, but because the underlying permissions and publication choices were already too broad.
Second, ownership gets fuzzy. When a Copilot or data agent answer looks wrong, who owns the underlying dataset, semantic definition, or business logic?
Third, security assumptions drift across products. The Cloud Adoption Framework specifically recommends understanding the native access and security model of every Microsoft product that can access data products, including Fabric data agents (Microsoft Learn, Data Product Security Standards for Microsoft AI and Analytics). That is a direct warning against assuming one access pattern covers every downstream AI scenario.
The cost curve gets ugly after self-service usage scales. At that point, you are no longer fixing a few assets. You are dealing with exception handling, manual review layers, emergency access cleanups, and trust repair.
If you want to make that risk concrete for leadership, even a simple export of broad workspace assignments can be powerful. Here is a more Fabric-native pattern using the Power BI admin surface, which many Fabric estates already rely on for workspace governance review:
# Example pattern: review broad workspace access using Power BI admin APIs in a Fabric-aligned estate
# Requires appropriate Power BI/Fabric admin permissions and an access token.
$token = "<access_token>"
$headers = @{ Authorization = "Bearer $token" }
$groups = Invoke-RestMethod `
-Uri "https://api.powerbi.com/v1.0/myorg/admin/groups?`$top=5000" `
-Headers $headers `
-Method Get
$results = foreach ($g in $groups.value) {
$users = Invoke-RestMethod `
-Uri "https://api.powerbi.com/v1.0/myorg/admin/groups/$($g.id)/users" `
-Headers $headers `
-Method Get
foreach ($u in $users.value) {
[pscustomobject]@{
Workspace = $g.name
Principal = $u.identifier
PrincipalType = $u.principalType
AccessRight = $u.groupUserAccessRight
}
}
}
$overshared = $results | Where-Object {
$_.Principal -match "All|Everyone|External" -and $_.AccessRight -in @("Viewer","Member","Admin")
}
$overshared | Export-Csv -Path ".\fabric-workspace-access-review.csv" -NoTypeInformation
$overshared | Format-Table -AutoSize
“All Employees” and “External” assignments are not automatically wrong, but they should trigger review before AI features make those access paths more conversational and more visible.
Fabric data agents expose the governance truth fast
If you want the clearest proof that AI readiness depends on governed access, look at Fabric data agents.
The concept page for Fabric data agents explains the supported sources and interaction model for conversational Q&A over governed enterprise data (Microsoft Learn, Fabric data agent creation). The how-to page then shows how to create a Fabric data agent over those sources (Microsoft Learn, Create a Fabric data agent).
That matters because data agents collapse the distance between “data exists somewhere” and “a user can ask a question about it.”
This is why I tell leaders something blunt: if you are uncomfortable with what a Fabric data agent could retrieve, summarize, or help infer from your environment, the problem is not the agent. The problem is your protection model.
Data agents do not invent governance gaps. They reveal them quickly.
And Microsoft’s guidance around Copilot in Fabric is consistent on this point. There is documented privacy, security, and responsible AI guidance for Copilot in Fabric generally, plus workload-specific guidance for data warehouse and data science scenarios before organizations scale broad business use (Microsoft Learn, Privacy, Security, and Responsible AI Use of Copilot in Fabric; Privacy, Security, and Responsible AI Use of Microsoft Copilot in Microsoft Fabric in the Data Warehouse Workload; Privacy, security, and responsible use of Copilot for Data Science).
Model choice still matters after the protection basics are in place, but it is not the first control point most enterprises should optimize.
Built-in protection is a speed advantage
A lot of teams still frame governance as friction. In Fabric, that is backwards.
Built-in protection is a speed advantage because it reduces rework. If classification, labeling, access control, and processing standards are handled natively and consistently, you need fewer bespoke guardrails later. You also avoid duplicating policy logic across analytics tools, retrieval layers, and assistant experiences.
This is especially important in regulated sectors. Microsoft explicitly positions Fabric for financial services as a platform that supports AI adoption with integrated analytics and AI capabilities in regulated environments (Microsoft Learn, Microsoft Fabric - Microsoft for Financial Services).
A practical operating model looks like this:
- Define what data can enter OneLake.
- Standardize how it is refined.
- Define how it is published as a trusted data product.
- Assign explicit owners.
- Apply classification and sensitivity metadata consistently.
- Understand the native access model of every product that can query or present that data, including Fabric data agents.
- Measure drift continuously.
If you want to turn governance findings into action, a compact remediation report helps stewards move faster:
# Convert governance findings into a compact remediation report for stewards
assets = [
{"name": "SalesLakehouse", "owner": "alex@contoso.com", "classification": "Confidential", "sensitivity": "High"},
{"name": "HRWarehouse", "owner": "", "classification": "Restricted", "sensitivity": "High"},
{"name": "MarketingModel", "owner": "mia@contoso.com", "classification": "", "sensitivity": "Medium"},
]
def remediation_row(asset):
gaps = []
if not asset["owner"]:
gaps.append("Assign owner")
if not asset["classification"]:
gaps.append("Apply classification")
if not asset["sensitivity"]:
gaps.append("Apply sensitivity label")
return {"asset": asset["name"], "actions": "; ".join(gaps) or "None"}
report = [remediation_row(a) for a in assets]
for row in report:
print(row)
The goal is not to create a giant governance program deck. The goal is to produce a short, actionable list of missing controls per asset and route it to the right owner.
A practical operating model for AI-ready data protection
Here is the model I recommend for Fabric-first organizations:
1. Govern data products, not just storage locations
The unit of trust is the published data product: lakehouse, warehouse, semantic model, KQL database, or other governed asset that users and AI systems actually consume.
2. Make ownership explicit
Every AI-consumable asset needs a named owner and stewarding path. If an answer is wrong or risky, accountability cannot be ambiguous.
3. Standardize processing before publication
The Cloud Adoption Framework is direct here: define organizationwide standards for what enters OneLake, how it is refined, and how it is published (Microsoft Learn, Data Processing Standards for AI and Analytics).
4. Understand product-specific security models
Do not assume all Microsoft data experiences behave identically. The Cloud Adoption Framework explicitly says to understand the native access and security model of every product that can access data products, including Fabric data agents (Microsoft Learn, Data Product Security Standards for Microsoft AI and Analytics).
5. Measure readiness by protection coverage
Do not report only on deployment milestones like workspace count, lakehouse count, or Copilot enablement. Measure:
- Percent of AI-consumable assets with named owners
- Percent with classification and sensitivity metadata
- Count of broad workspace and item-level assignments
- Drift between policy intent and actual access
- Number of assets approved for AI use versus blocked pending remediation
That is what AI readiness looks like in practice.
The executive takeaway
The winners in enterprise AI will not be the organizations with the most pilots. They will be the ones whose data protection model survives scale.
That is why I take a hard line on this: in Fabric, built-in protection features are not sidecar compliance tooling. They are activation infrastructure for AI.
If your estate is Fabric first, then classification, labeling, access control, and processing standards are the architecture that determines whether Copilot, data agents, retrieval, and analytics can be trusted at scale.
Govern early inside the platform, or pay later when AI exposes every unresolved data control gap.
Rate your team’s current state on this from 1 to 5: how much of your Fabric estate is actually protected well enough for conversational AI and Copilot to use safely?
And more importantly: what is the biggest blocker in your Fabric estate today: ownership, labeling, workspace access, or product-specific security? I’d be interested in the policy pattern or rollout lesson that has worked best for your team.
#MicrosoftFabric #EnterpriseAI #Datagovernance
Sources & References
- Microsoft Fabric - Microsoft for Financial Services
- IDEAS journey to a modern data platform with Fabric - Microsoft Fabric
- Fabric data agent creation - Microsoft Fabric
- Data for AI and Analytics - Guidance to set your organization's data strategy for Ai and analytics - Cloud Adoption Framework
- Data Product Security Standards for Microsoft AI and Analytics - Cloud Adoption Framework
- Create a Fabric data agent - Microsoft Fabric
- Data Processing Standards for AI and Analytics - Cloud Adoption Framework
- Privacy, Security, and Responsible AI Use of Copilot in Fabric - Microsoft Fabric
- Privacy, Security, and Responsible AI Use of Microsoft Copilot in Microsoft Fabric in the Data Warehouse Workload - Microsoft Fabric
- Privacy, security, and responsible use of Copilot for Data Science - Microsoft Fabric
Try it yourself
Run this tutorial as a Jupyter notebook: Download runbook.ipynb (26 cells, 20 KB).



