How to expose governed data to copilots with REST, GraphQL, and MCP from one Azure service
How to expose governed data to copilots with REST, GraphQL, and MCP from one Azure service

Governed data access is the product.
The enterprise copilot race is creating a false choice: move fast with loose data access, or keep governance and slow everything down. I think the better pattern is simpler: expose governed data once from a controlled Azure service, then let REST, GraphQL, and agent-facing tool interfaces sit on top of that same boundary.
Why the copilot boom is really a data-governance test
The market loves to debate model brands, copilots, and agent frameworks. That is rarely the first enterprise decision that matters.
The harder question is this: can your platform expose trusted enterprise data once, with auditability, least privilege, and policy enforcement, and then serve multiple AI consumers without creating a new security model for each one?
That pressure is no longer theoretical. Microsoft is clearly pushing enterprise agent workflows in Foundry and related tooling, which is a signal that governed access to real business data is becoming a delivery problem, not just an innovation-lab experiment.
My view: the strategic decision is not which copilot brand wins. It is whether your architecture can expose governed, auditable data access through multiple interface patterns without multiplying risk.
I recently saw a platform team build separate “AI data access” paths for a sales copilot, a service assistant, and an analytics bot. Within weeks, the same customer record had three different entitlement rules depending on which assistant asked for it.
That is not an AI problem. It is an exposure-pattern failure.
The pattern: one governed Azure service, many interfaces
For many enterprise cases, I would start with this reference pattern:
- Azure SQL as the governed data anchor
- Azure App Service as the controlled compute layer
- A custom agent-tool endpoint hosted in App Service, potentially using MCP-style patterns where appropriate
- Azure API Management as a shared policy enforcement point for selected interfaces
- Microsoft Entra identity across the path
The important nuance: this is an architectural choice, not a turnkey Azure product stack. Azure gives you the building blocks, but “one governed service, many interfaces” still requires implementation decisions, especially for GraphQL and agent tooling.
The shape looks like this:
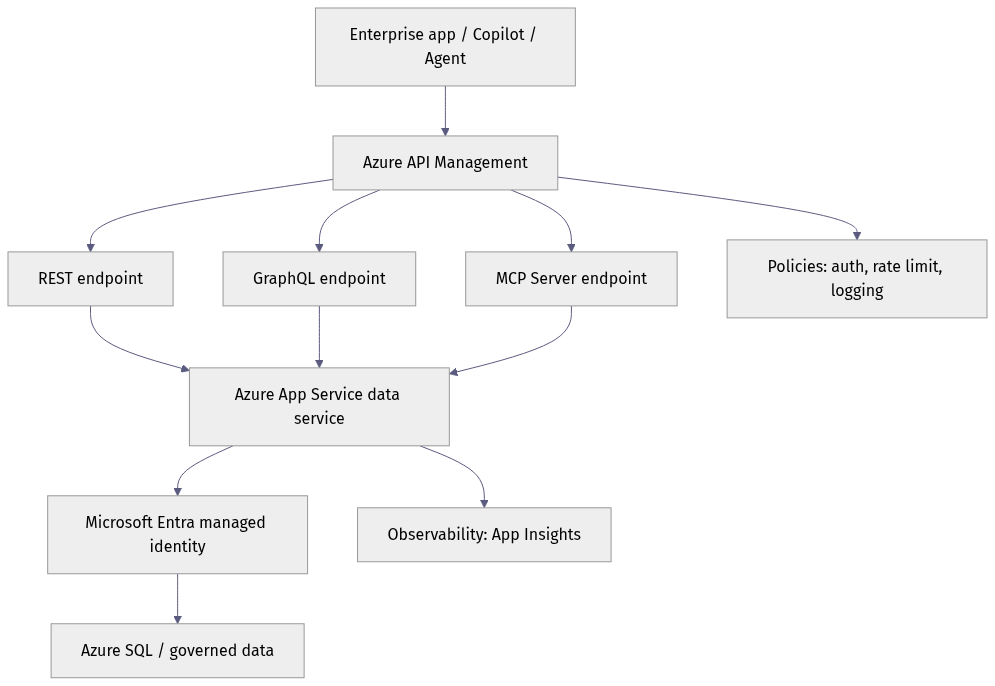
REST, GraphQL, and agent-tool calls should not hit random backends with inconsistent auth. They should converge on one service boundary, one identity model, and one observability path.
Azure API Management can help here, but it is not magic unification. It is a policy and mediation layer. For REST, that fit is straightforward. For GraphQL, you still need to decide where the schema and resolvers live. For MCP or MCP-like tool exposure, you may need adapters, custom mediation, or selective exposure depending on how your tool server is implemented.
Why Azure SQL is a credible anchor
For enterprise copilots, the governed data anchor should usually sit closer to the operational source of truth than to a growing sprawl of copied AI-ready marts.
Azure SQL is a pragmatic anchor because it already fits how many enterprises manage important data:
- It often sits near systems of record
- It supports mature security controls
- It integrates with Entra-backed identity
- It fits existing stewardship and operational ownership models
That matters. Every time you create a separate data product just to satisfy a copilot, you create synchronization lag, policy drift, and another place for permissions to go wrong.
A practical pattern is to run your service layer in App Service with a system-assigned managed identity, then grant that identity only the minimum rights it needs in Azure SQL.
For example, enable a system-assigned managed identity on the App Service:
# Enable a system-assigned managed identity for an App Service
$resourceGroup = "rg-governed-data"
$appName = "data-service-prod"
$app = Update-AzWebApp -ResourceGroupName $resourceGroup -Name $appName -AssignIdentity $true
$principalId = $app.Identity.PrincipalId
"Managed identity enabled for $appName"
"PrincipalId: $principalId"
Then configure non-secret application settings separately:
# Configure App Service settings without storing database passwords
$resourceGroup = "rg-governed-data"
$appName = "data-service-prod"
$appSettings = @{
"SQL_SERVER_FQDN" = "contoso-sql.database.windows.net"
"SQL_DATABASE_NAME" = "GovernedSales"
"GRAPHQL_ENABLED" = "true"
"AGENT_TOOLS_MODE" = "restricted"
"AUDIT_MODE" = "structured"
}
Set-AzWebApp `
-ResourceGroupName $resourceGroup `
-Name $appName `
-AppSettings $appSettings | Out-Null
"Updated app settings for $appName"
Then create a contained database user for that managed identity and grant least privilege. The SQL below is illustrative T-SQL and should be executed by an Entra-enabled admin connection to the target database:
CREATE USER [data-service-prod] FROM EXTERNAL PROVIDER;
ALTER ROLE db_datareader ADD MEMBER [data-service-prod];
DENY INSERT, UPDATE, DELETE TO [data-service-prod];
That is not glamorous, but it is the kind of discipline that keeps an assistant integration from quietly becoming a write path into production data.
Microsoft’s managed identity documentation and Azure SQL Entra authentication guidance make this pattern well-supported for secretless service-to-database access. That is a much stronger foundation than embedding credentials in app config.
REST, GraphQL, and MCP are not rival bets
These are not winner-take-all choices. They are different access modes for different consumers.
REST
Use REST for stable, contract-driven business operations where policy, versioning, and interoperability matter most.
GraphQL
Use GraphQL when clients need flexible shapes from the same governed domain. But be precise about where it lives: in this pattern, GraphQL would typically be implemented in the App Service layer, with resolvers calling the same governed business logic as REST. Governance is not provided by GraphQL itself; it has to be enforced in resolvers, field access rules, query depth limits, and downstream authorization checks.
MCP or MCP-style tool interfaces
Use these for agent scenarios where discoverable tools and structured invocation matter more than traditional endpoint ergonomics. In Azure, this is currently best treated as a custom or emerging implementation pattern, not a standard Microsoft product blueprint. If you expose tool endpoints through APIM, expect mediation and adapter work rather than assuming turnkey support.
Here is a simple illustration of the same governed service being called through REST and GraphQL:
# Compare governed REST and GraphQL calls against the same Azure-backed service
import requests
base_url = "https://api.contoso.azure-api.net/data"
token = "eyJhbGciOi..." # Entra access token for the client/app
headers = {"Authorization": f"Bearer {token}"}
rest = requests.get(
f"{base_url}/customers/CUST-1001?include=openOrders",
headers=headers,
timeout=15,
)
print("REST status:", rest.status_code)
print("REST shape:", rest.json())
graphql_query = """
query GetCustomer($id: ID!) {
customer(id: $id) {
id
name
riskTier
openOrders { id total status }
}
}
"""
graphql = requests.post(
f"{base_url}/graphql",
headers={**headers, "Content-Type": "application/json"},
json={"query": graphql_query, "variables": {"id": "CUST-1001"}},
timeout=15,
)
print("GraphQL status:", graphql.status_code)
print("GraphQL shape:", graphql.json())
The backing service can be the same even when the client ergonomics differ. That is the point.
And here is an illustrative MCP-style tool invocation over HTTP:
# Invoke an MCP-style tool over HTTP to expose governed SQL-backed data to an agent
import requests
mcp_endpoint = "https://sql-mcp.contoso.azurewebsites.net/mcp/tools/queryCustomer"
payload = {
"arguments": {
"customerId": "CUST-1001",
"projection": ["name", "riskTier", "openOrders"],
}
}
headers = {
"Authorization": "Bearer eyJhbGciOi...",
"Content-Type": "application/json",
}
result = requests.post(mcp_endpoint, headers=headers, json=payload, timeout=20)
result.raise_for_status()
tool_result = result.json()
print("Tool:", tool_result.get("tool"))
print("Governed output:", tool_result.get("content"))
This should be read as an implementation example, not proof of a Microsoft-standard “SQL MCP Server” product pattern. The architectural idea is constrained tool access through a governed service boundary, not direct database access from the agent runtime.
The real risk: identity and tenant governance
The hardest part of copilot data access is usually not protocol selection. It is identity design.
Least privilege has to exist at every layer:
- Database roles in Azure SQL
- Managed identities for hosted services
- Narrow API scopes for clients
- Resolver- and tool-level authorization
- Tenant consent controls in Entra
- Logging that does not leak secrets or tokens
A discoverable tool is still an execution surface. If the tool is over-privileged, the architecture is over-privileged.
That is why I would insist on tenant-level guardrails:
- Admin consent workflows for sensitive permissions
- App registration hygiene and ownership
- Conditional Access where appropriate
- Secretless auth whenever possible
- Auditable service principals and managed identities
- Correlation IDs and structured logs on governed requests
Even for plain REST, small disciplines matter:
# Call a governed REST endpoint with explicit correlation and policy-friendly headers
import uuid
import requests
endpoint = "https://api.contoso.azure-api.net/data/orders?top=5&status=Open"
headers = {
"Authorization": "Bearer eyJhbGciOi...",
"x-correlation-id": str(uuid.uuid4()),
"x-client-scenario": "copilot-order-summary",
}
response = requests.get(endpoint, headers=headers, timeout=10)
response.raise_for_status()
for order in response.json().get("value", []):
print(f"{order['id']} | {order['customerName']} | {order['total']}")
APIM policies are useful here for authentication, rate limiting, header inspection, transformation, and logging, but they do not replace authorization logic in your service or resolvers. They are one control point, not the whole control system.

Trust has to extend below the API surface
Governed exposure is not just an API design problem. It is also an infrastructure trust problem.
That is why deeper Azure trust primitives matter for sensitive workloads, including hardware-backed key protection and clearer trust boundaries. A “secure API” sitting on weak identity handling or poor secret hygiene is not a secure system.
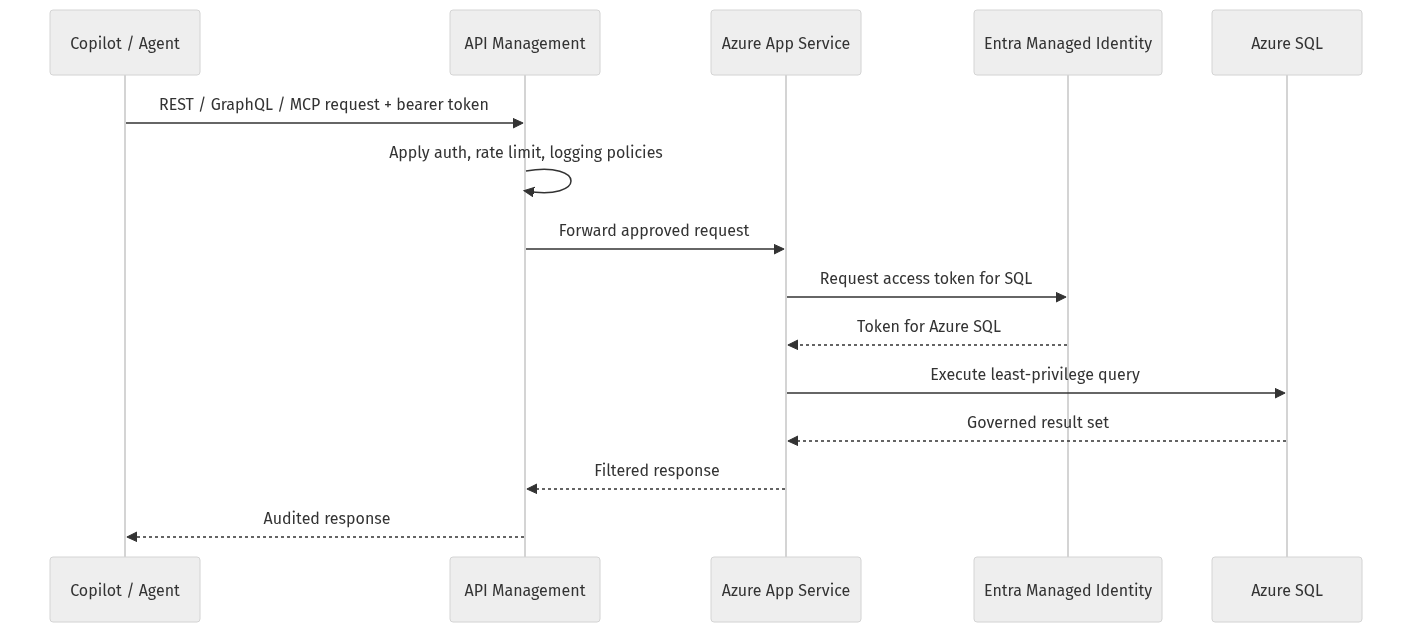
The operational sequence you want is simple: approved request, policy enforcement, managed identity token acquisition, least-privilege query, filtered response, audit trail.
Where this pattern is not ideal
I still prefer this pattern for many enterprise scenarios, but not all of them.
I would separate exposure layers when you have extreme performance isolation requirements, hard domain boundaries, materially different release cadences, or cases where one consumer type genuinely needs an independent lifecycle and control model. Sometimes one governed core with multiple interfaces is elegant. Sometimes it becomes an unnecessary coupling point.
The point is not “always one stack.” The point is to avoid accidental governance sprawl when separation is not actually required.
Sovereignty, cost, and operating reality
In multinational, regulated, or partially disconnected environments, this design gets more compelling.
Residency, compliance, and operational separation still matter. A single controlled service with multiple interfaces can reduce duplicated policy implementation across channels. You do not want one residency story for REST, another for GraphQL, and a third for agent tools unless there is a real reason.
There is also a cost argument. Separate data-access stacks for every copilot channel create duplicate integration work, duplicate policy surfaces, duplicate support paths, and duplicate audit effort.
What I would standardize now
If I were setting enterprise guidance today, I would standardize on this as a default reference pattern:
- Azure SQL as the governed data anchor
- Azure App Service for the controlled service layer
- GraphQL implemented in that service layer when flexible retrieval is needed
- Agent-tool endpoints implemented as custom or emerging patterns, potentially MCP-aligned, behind the same governance boundary where practical
- Azure API Management as a shared policy enforcement point where it adds value
- Entra-based identity, managed identities, and centralized audit as non-negotiables
Then I would choose interfaces by consumer type:
- REST for transactional systems and stable operational contracts
- GraphQL for flexible app retrieval and consumer-shaped responses
- MCP-style tools for agent use where discoverability and structured invocation matter
And I would force every new copilot initiative to answer one question before any demo is funded:
Which governed service owns data exposure and policy enforcement?
That decision will outlast model cycles and UI trends.
The teams that win will not be the ones with the flashiest copilot demos. They will be the ones that make governed data reusable across many copilots without re-architecting trust every time.
Which layer would you centralize first in your environment, and why: the governed data service, the identity model, or the policy gateway?
#EnterpriseAI #DataArchitecture #AzureSQL #APIM #GraphQL #MCP
Sources & References
- Managed identities for Azure resources
- Tutorial: Use managed identity to connect an Azure web app to Azure SQL Database without secrets
- Azure API Management policies
- Import a GraphQL API in Azure API Management
- Model Context Protocol specification
- Enforcing trust and transparency: Open-sourcing the Azure Integrated HSM
- OpenAIs GPT-5.5 in Microsoft Foundry: Frontier intelligence on an enterprise ready platform
- Microsoft Discovery: Advancing agentic R&D at scale
- Introducing Azure Accelerate for Databases: Modernize your data for AI with experts and investments
- Cloud Cost Optimization: Principles that still matter
Try it yourself
Run this tutorial as a Jupyter notebook: Download runbook.ipynb (27 cells, 20 KB).



