Three full-stack data platforms in a weekend: what Fabric and Azure AI Foundry enable for rapid delivery
Three full-stack data platforms in a weekend: what Fabric and Azure AI Foundry enable for rapid delivery

Three business-facing data platforms in a weekend is not a staffing miracle. It is a platform architecture outcome.
The old explanation for slow delivery was “we need more engineers.” I think that is increasingly wrong. Fabric and Azure AI Foundry are changing the delivery math by collapsing handoffs between data, AI, APIs, and app surfaces that used to consume most of the calendar.
The weekend-delivery claim is really about coordination drag
A “full-stack data platform” here is not just a lakehouse or a dashboard. It is the combination of:
- data ingestion and storage
- transformation and semantic access
- AI capability or model-backed workflow
- API exposure and integration controls
- a business-facing app, copilot, or operational experience
That stack used to require too many seams. One team landed data. Another modeled it. Another exposed it through APIs. Another experimented with AI. Another built the app. Security reviewed each layer separately. The elapsed time was dominated by handoffs, approval loops, and integration rewrites, not by typing code.
My opinion is simple: rapid full-stack delivery is now a platform design choice, not just a team execution issue.
Fabric plus Azure AI Foundry matter because they shorten the path from data landing to governed AI consumption and business-facing delivery. That does not remove the need for architecture discipline. It removes unnecessary waiting.
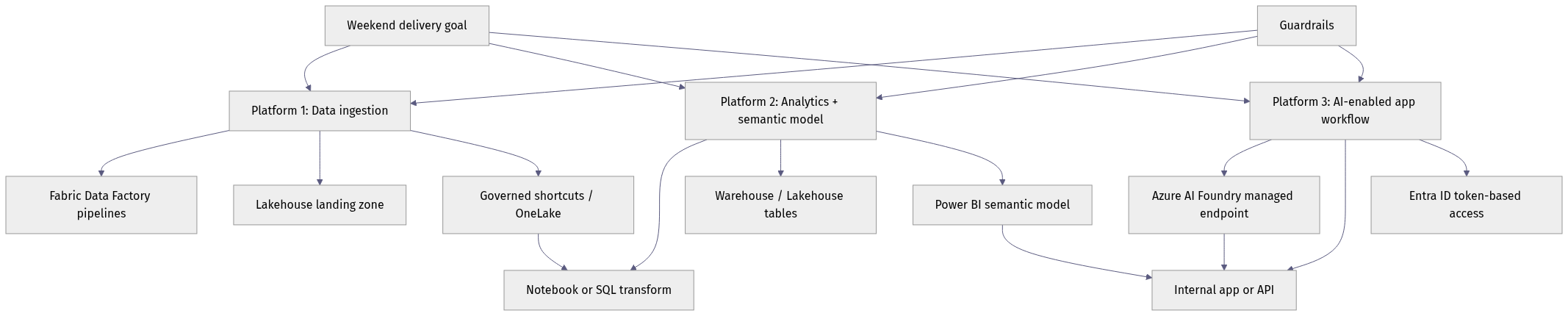
What matters is the short path between ingestion, curation, semantic access, AI endpoint consumption, and app delivery, with guardrails spanning all three. Fewer product boundaries usually means fewer project boundaries.
Why this moment is different
The convergence is now visible in the platform itself.
Azure API Management is being positioned not only for traditional APIs, but also for AI models, tools, and agents. That is a strong signal that governance and integration are converging instead of remaining separate delivery tracks. Internal apps increasingly need both classic APIs and governed AI endpoints in the same architecture.
The same pattern shows up in data modernization. Azure Accelerate for Databases frames database modernization as part of AI readiness, which is exactly right: the bottleneck for rapid app delivery is often source data quality, schema readiness, and operational access patterns, not model availability alone.
And sovereign and compliance constraints are no longer side cases. Microsoft Sovereign Private Cloud with Azure Local shows that platform convergence is being pushed into environments where control, residency, and disconnected operations matter.
This is not a marketing milestone. It is a practical inflection point for enterprise architects.
A field example made this obvious to me: in Q1, a six-person internal platform team at a manufacturing client rebuilt a supplier-risk workflow in 9 days after a previous attempt had stalled for 11 weeks waiting on separate API gateway, model access, and data-approval decisions.
Integrated platforms beat fragmented stacks for time-to-value
Best-of-breed is still valid. It is just overrated for many internal business platforms.
If your stack is composed of a separate lakehouse, separate orchestration tool, separate vector layer, separate model gateway, separate API gateway, separate semantic layer, and separate app tooling, you may get local optimality in each component. But you usually pay for it in:
- decision latency
- integration overhead
- duplicated governance
- cross-team dependency management
That is why integrated capability often beats theoretical component optimality.
For internal business-facing platforms, the biggest advantage is not one killer feature. It is a smaller number of control surfaces across identity, data access, API exposure, app delivery, and AI access. When those layers align by default, delivery accelerates.

That does not mean integrated should be the default everywhere. It is often the wrong answer when you need highly specialized ML tooling, already run a mature multi-vendor estate with strong operating discipline, or must preserve strict separation of duties across platform layers. In those environments, the integration tax may be lower than the switching or consolidation tax.
A hands-on pattern: assemble the data plane first
If you want to ship quickly, start with a minimal but governed data product. Fabric changes the build sequence because ingestion, storage, transformation, and consumption can sit closer together than they did in older Azure-centric patterns.
A simple illustration is landing operational data into a lakehouse-friendly Parquet structure, then promoting it into a KPI-ready dataset. These examples are conceptual sketches of landing and curation patterns, not canonical production Fabric notebook or pipeline implementations.
First, land the raw operational data.
# Fabric-style ingestion: land operational data into a lakehouse-friendly parquet dataset
import pandas as pd
from pathlib import Path
orders = pd.DataFrame(
[
{"order_id": 1001, "customer": "Contoso", "amount": 420.50},
{"order_id": 1002, "customer": "Fabrikam", "amount": 199.99},
]
)
output = Path("Files/bronze/orders")
output.mkdir(parents=True, exist_ok=True)
orders.to_parquet(output / "orders_2026_05_06.parquet", index=False)
print(f"Wrote {len(orders)} rows to {output}")
The point is not sophistication. It is a repeatable landing pattern that can feed downstream transforms and semantic models without format churn.
Then create a lightweight curated layer that business apps can actually use.
# Lightweight transform: promote bronze data into a curated KPI-ready dataset
import pandas as pd
bronze = pd.DataFrame(
[
{"order_id": 1001, "customer": "Contoso", "amount": 420.50},
{"order_id": 1002, "customer": "Fabrikam", "amount": 199.99},
{"order_id": 1003, "customer": "Contoso", "amount": 80.00},
]
)
silver = (
bronze.groupby("customer", as_index=False)
.agg(total_revenue=("amount", "sum"), order_count=("order_id", "count"))
.assign(avg_order_value=lambda df: df["total_revenue"] / df["order_count"])
)
print(silver.to_string(index=False))
The “silver” output is immediately closer to a semantic model, KPI tile, or app-facing API payload. That is where Fabric helps in practice: less negotiation over where the workload belongs and fewer transitions before the business sees something useful.
This is also where database modernization becomes operationally important. If source systems are brittle, undocumented, or inaccessible, no AI platform will save your delivery timeline.
The missing middle: APIs, agents, and app surfaces
A fast data platform is useless if business apps cannot consume it safely and consistently. The missing middle is the layer between curated data and end-user experience: APIs, governed AI endpoints, reusable service boundaries, and app integration patterns.
That is why Azure API Management’s positioning around APIs, AI models, tools, and agents matters. The integration layer is now part of the AI architecture, not an afterthought.
Here is the interaction pattern I recommend for internal AI-enabled apps: the app gets identity, reads approved business context from a curated data product, sends prompt plus context to a governed AI endpoint, and logs metadata rather than sensitive payloads wherever possible.
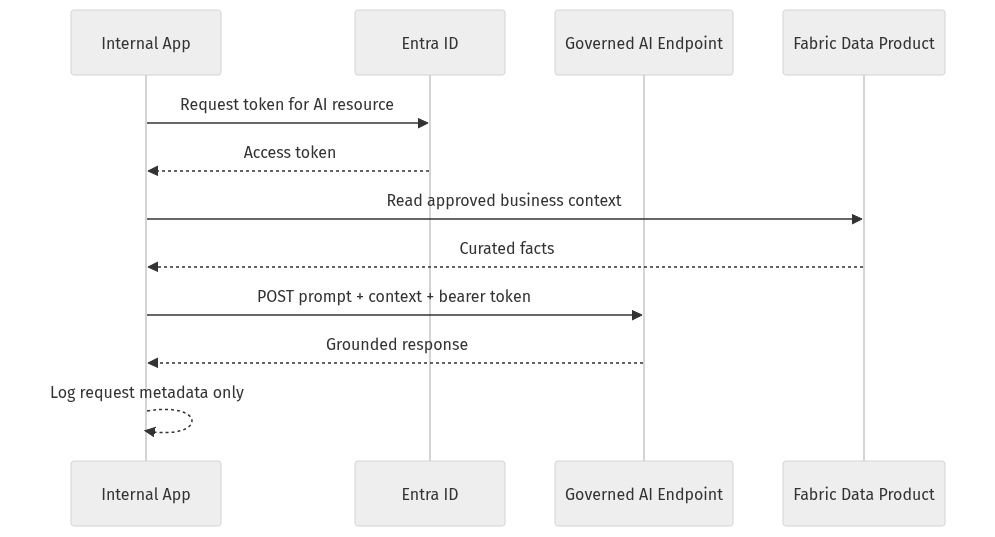
Identity and data curation happen before the model call, not after. That is the right order.
If you want an implementation sketch, wrap AI access behind a small internal API rather than letting every app call the model endpoint directly.
# Internal API pattern: wrap AI access behind a small service boundary with approved context
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class AskRequest(BaseModel):
account_id: str
question: str
@app.post("/copilot/ask")
def ask(req: AskRequest):
approved_context = {"account_id": req.account_id, "source": "curated_customer_360"}
answer = {
"question": req.question,
"answer": f"Governed response for {req.account_id}",
"context_used": approved_context,
}
return answer
This pattern helps stop connector sprawl and app-by-app reinvention. Power Apps, internal web apps, and workflow tools move faster when they consume a stable internal service contract instead of each implementing its own prompt, token, and context logic.
Governance reality check: faster delivery raises the stakes on security
If build speed goes up, security has to move earlier. Identity hardening, app-consent controls, token protection, and early security review are not optional because the platform is integrated. They matter more because the blast radius of bad defaults is larger.
Design-time questions matter:
- Who can create app registrations?
- Who can grant admin consent?
- Which service principals have no owners?
- How are tokens acquired, stored, and rotated?
- Which AI endpoints are exposed to which apps?
- How is data access audited across Fabric, APIs, and app layers?
A lightweight governance check can catch obvious identity posture problems early. Reviewing app registrations with Microsoft Graph access is a practical first pass.
# Governance check: review app registrations for broad Graph permissions and risky consent posture
param(
[string]$TenantId = "<tenant-id>"
)
Connect-MgGraph -TenantId $TenantId -Scopes "Application.Read.All","Directory.Read.All" | Out-Null
$apps = Get-MgApplication -All
$graphAppId = "00000003-0000-0000-c000-000000000000"
$apps | ForEach-Object {
$graphAccess = $_.RequiredResourceAccess | Where-Object { $_.ResourceAppId -eq $graphAppId }
if ($graphAccess) {
[pscustomobject]@{
DisplayName = $_.DisplayName
AppId = $_.AppId
GraphAccess = ($graphAccess.ResourceAccess.Id -join ",")
}
}
} | Format-Table -AutoSize

This kind of script is useful conceptually, but in a production review you would resolve those permission IDs to readable Microsoft Graph scopes or app roles, distinguish delegated from application permissions, and check consent posture explicitly. That is the level where “interesting inventory” becomes “actionable governance.”
Integrated platforms accelerate good patterns and bad patterns equally. Put the guardrails in before broad enablement.
Cost, sovereignty, and operating model still decide whether speed survives reality
A platform delivered quickly is only a success if it remains governable and financially sustainable.
Cloud cost optimization still matters in the AI era because model calls, storage growth, and duplicated environments can quietly erase the business case if nobody owns lifecycle policy and usage discipline. The same goes for sovereignty and regulated operations, where control, residency, and operating constraints can override pure delivery speed.

So the executive question is no longer “can we build it fast?” The real question is “can we scale the governance and economics of what we build fast?”
My decision framework for architects and platform leads
Choose integrated platform patterns when your goal is to ship multiple internal data products and business apps quickly with a small number of reusable controls. In that scenario, Fabric plus Azure AI Foundry is compelling not because every component is the absolute best at every niche task, but because the whole operating model reduces coordination cost.
Use this evaluation lens:
- How many teams must approve the path from source data to app?
- How many identity and governance surfaces must be configured?
- How many custom integrations are required before the first business-facing release?
- How long until a real user can interact with a governed app, not just a notebook demo?
Choose fragmented best-of-breed only when one of these is true:
- you need extreme specialization
- you have meaningful sunk investment that already works
- regulatory or operational constraints force separation
Otherwise, the integrated stack usually wins.
That is my core claim: over the next year, the winners will not be the teams with the most heroic execution. They will be the teams that treat platform convergence as an execution multiplier while keeping governance discipline intact.
If your organization says it wants faster internal AI and data delivery, stop asking only whether the team is capable. Ask whether the platform architecture is still designed around handoffs.
Where has your delivery time actually gone down most: data prep, API exposure, or AI endpoint governance?
#AzureAI #EnterpriseAI #DataArchitecture
Sources & References
- Microsoft named a Leader in the IDC MarketScape: Worldwide API Management 2026 Vendor Assessment
- Introducing Azure Accelerate for Databases: Modernize your data for AI with experts and investments
- Microsoft Sovereign Private Cloud scales to thousands of nodes with Azure Local
Try it yourself
Run this tutorial as a Jupyter notebook: Download runbook.ipynb (23 cells, 19 KB).



