Should your database be the prompt? Rethinking NL2SQL with SQL MCP Server
Should your database be the prompt? Rethinking NL2SQL with SQL MCP Server
Your database should not be the prompt.
NL2SQL used to be a clever demo. Now that teams are discussing real copilots over production data, the question is no longer whether a model can write SQL. It is whether your architecture can survive what happens when it does.
For a while, the industry focused on “Can the model generate the query?” That is now the least interesting question. The real issue is whether you want schema, semantics, permissions, and execution authority collapsing into one opaque prompt exchange.
My view is simple: in enterprise systems, the database should not become the prompt surface. Once AI touches production data, this stops being a text-generation problem and becomes a governance and execution problem.
That is why SQL MCP Server is interesting. Its documentation is explicit that it does not support direct NL2SQL. Instead, it pushes a mediated pattern: agents use approved tool contracts to reach SQL data through a governed interface. Microsoft is one strong example here, not the only valid implementation. The broader architectural principle matters more than the product name.
Why direct NL2SQL fails in production
Prototype logic is easy:
- give the model the schema
- add examples
- let it generate SQL
- see if the answer looks right
That can work in a benchmark or internal demo. It does not answer the production questions that actually matter:
- Can it be authorized safely?
- Can you limit blast radius when it fails?
- Can you audit every data action?
- Can you control cost and concurrency?
- Can you explain why a result was returned?
Accuracy is only one dimension. A model that produces syntactically valid SQL most of the time is still an operational problem if the rest can trigger wide scans, expose sensitive schema details, or bypass business semantics.
In one analytics review I saw, a team had a working text-to-SQL demo against a sales mart in under two weeks. The next month was spent adding permission checks, timeouts, and logging after a generated query hit a fact-table scan they had never budgeted for.
That is the real pivot. Production NL2SQL is not “prompt engineering for data.” It is architecture for AI-mediated data access.
The seductive shortcut: making the database part of the prompt
Direct NL2SQL is appealing because it demos beautifully. Expose a schema, add table descriptions, maybe retrieve a few examples, and suddenly users can ask business questions in plain English. It feels like self-service analytics without the semantic modeling work.
But the shortcut hides the real tradeoff: the moment you make your database part of the prompt surface, you expand the attack, leakage, and ambiguity surface too.
The core problems are straightforward.
First, schema becomes model-visible context. Table names, columns, relationships, and descriptions are no longer just implementation details. In many enterprises, that context is sensitive on its own.
Second, user intent and execution authority get coupled. The same interaction that interprets the question also determines what gets executed. That is too much power in one probabilistic step.
Third, prompt injection stops being just an LLM concern and becomes a data-access concern. If system instructions, retrieved schema, examples, and user text all compete inside one prompt, instruction hierarchy gets harder to reason about.
Fourth, cost risk becomes open-ended. Models do not naturally optimize for warehouse spend, lock contention, or query-plan stability. If they can synthesize arbitrary joins and retries, your database performance becomes part of the experiment.
And finally, least privilege gets blurry. Enterprises do not just care whether a query is valid. They care whether the caller should have been able to ask it, whether the result should have been masked, and whether the operation should have been possible at all.
To be fair, direct NL2SQL can still be acceptable in low-risk, sandboxed, read-only, or internal analytics contexts where the blast radius is small and the data is non-sensitive. But that is a very different claim from saying it belongs anywhere near production business workflows by default.
What SQL MCP Server gets right
What makes SQL MCP Server notable is not that it helps a model “do SQL.” It is that it refuses the most dangerous default.
The design move is separation:
- language understanding happens in the agent layer
- database interaction happens through a mediated tool contract
- execution is constrained by approved operations and parameters
- the database is reached through a governable interface, not arbitrary generated SQL
That is the mental model shift. The model should decide which approved tool to use, not improvise raw SQL against production data.
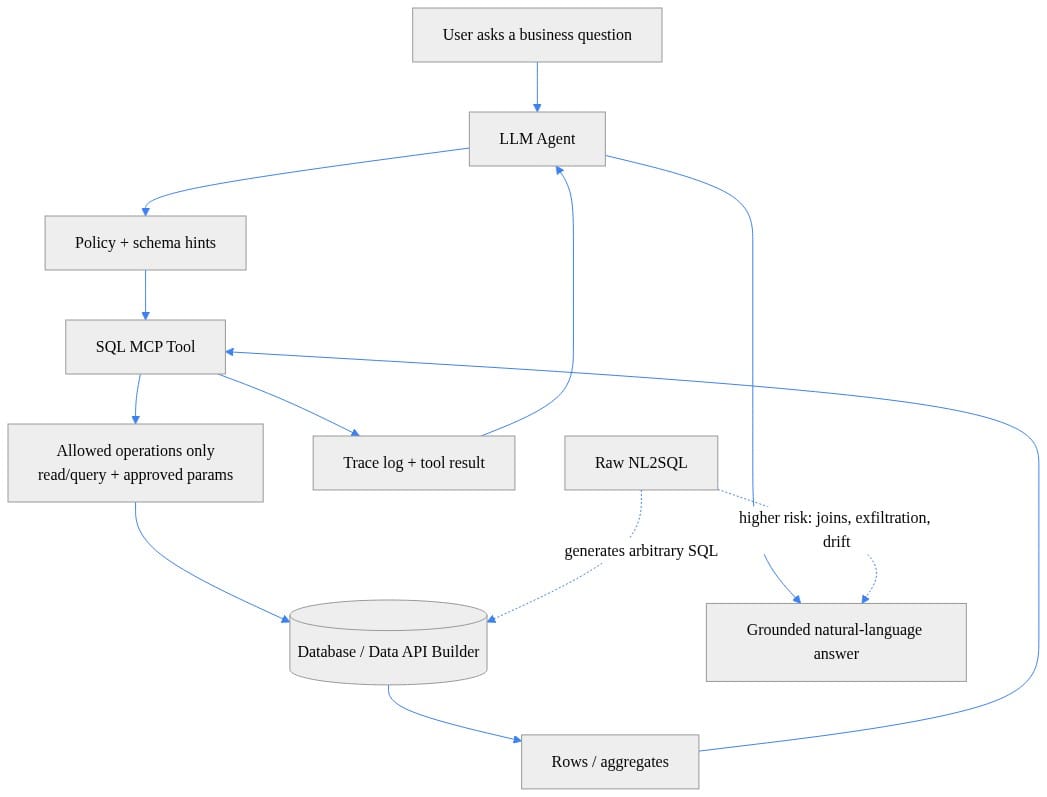
The important point is not Microsoft-specific. SQL MCP Server is one implementation of a broader mediated-access pattern that many teams should be aiming for: bounded tools, validated parameters, policy enforcement, and traceability between the model and the data.
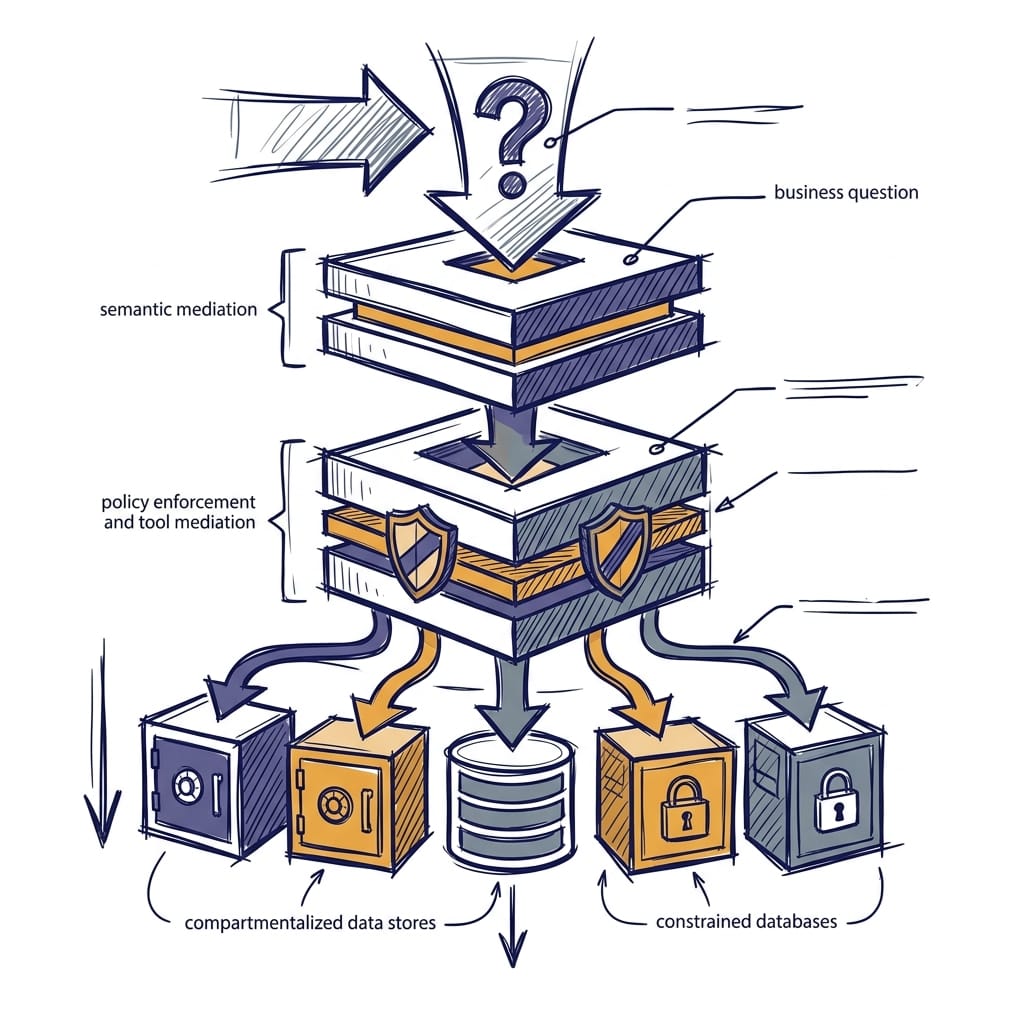
The reference pattern I would use
If I were designing this today, I would not start with “How do we get the model to write better SQL?” I would start with “What are the smallest approved operations that answer the business questions we care about?”
A practical enterprise pattern looks like this:
- A user asks a business question.
- The application resolves intent against a semantic layer where terms like revenue, active customer, or quarter are defined.
- The agent selects from approved tools such as
sales_by_regionortop_customers, not arbitrary SQL text. - Policy validates parameters like year ranges, limits, tenant scope, and access rights.
- A mediated SQL interface executes the approved operation.
- Native database controls such as RBAC, row-level security, masking, and workload governance still apply.
- The system logs tool choice, parameters, source entities, and answer provenance.
That is what a production architecture looks like. Natural language interpretation is separated from business meaning, execution authority, and enforcement.
Here is a small conceptual example of that pattern. It is illustrative pseudocode, not a product-specific SQL MCP implementation:
# Tool contract with explicit schema, parameter validation, and safe execution envelope.
from dataclasses import dataclass
from typing import Dict, Any
@dataclass(frozen=True)
class ToolSpec:
name: str
description: str
params: Dict[str, str]
SQL_MCP_SPEC = ToolSpec(
name="sql_mcp.sales_by_region",
description="Returns revenue aggregated by region for an approved year.",
params={"year": "int between 2020 and 2030"}
)
def validate_params(params: Dict[str, Any]) -> Dict[str, Any]:
year = int(params["year"])
if year < 2020 or year > 2030:
raise ValueError("year out of approved range")
return {"year": year}
approved = validate_params({"year": "2025"})
print(SQL_MCP_SPEC)
print({"safe_request": approved})
What matters here is the shape of the contract. The tool is explicit. Parameters are validated. Execution happens inside a bounded envelope. That is much closer to a real control plane than “let the model write SQL and hope the prompt was good enough.”
Where AI SQL assistance still fits
None of this means AI should stay away from SQL.
It means we should stop collapsing very different use cases into one bucket.
AI assistance inside a governed development or administration tool can be extremely useful. Copilot-style help in SQL tooling supports drafting, explanation, troubleshooting, and workflow acceleration inside a managed experience.
That is not the same as exposing production business data to unconstrained natural-language querying.
Likewise, management-plane assistance over Azure SQL resources is different from letting a model freely generate analytical SQL against business datasets. Those are separate risk categories and should be treated that way.
The distinction matters because a lot of teams say “AI for SQL” when they actually mean one of three very different things:
- developer assistance
- management-plane operations
- end-user access to business data
Only the third one creates the full governance problem.
The principles I would enforce right now
If you are making this call today, I would be blunt:
- Prefer mediated operations over arbitrary SQL generation.
- Treat schema context as sensitive information, not harmless prompt filler.
- Define business meaning in semantic models or service contracts, not in the prompt.
- Enforce least privilege across model, tool, API, and database layers.
- Put cost controls and auditability into the architecture, not into wishful instructions.
- Design for failure first: prompt injection, over-broad retrieval, runaway query loops, and exfiltration attempts.
The database should remain a governed system of record, not a giant autocomplete target for a chatbot.
That is why SQL MCP Server matters strategically. Its value is not that it adds another AI integration point. Its value is that it reinforces a safer default: mediated, deterministic data access instead of direct NL2SQL against production systems.
Conclusion
The winning teams will not be the ones with the flashiest text-to-SQL demo. They will be the ones that build a control plane between AI agents and production data.
Your database should not be the prompt.
Use the model for intent. Use semantic layers for meaning. Use policy and mediated tools for execution. Whether you use SQL MCP Server or another equivalent pattern, the principle is the same: do not let arbitrary SQL generation become your production data interface.
Do you allow arbitrary SQL generation anywhere near production? If not, what controls do you require before exposing business data to agents?
#EnterpriseAI #DataArchitecture #AzureSQL
Sources & References
- SQL MCP Server overview - https://learn.microsoft.com/en-us/azure/data-api-builder/mcp/overview
- Intelligent Applications and AI - Azure SQL Database - https://learn.microsoft.com/en-us/azure/azure-sql/database/ai-artificial-intelligence-intelligent-applications
- Azure MCP Server tools for Azure SQL Database - https://learn.microsoft.com/en-us/azure/developer/azure-mcp-server/tools/azure-sql
- Scenarios - Copilot in SQL Server Management Studio - https://learn.microsoft.com/en-us/ssms/copilot/copilot-in-ssms-scenarios
- Quickstart - Azure AI Foundry - SQL MCP Server - https://learn.microsoft.com/en-us/azure/data-api-builder/mcp/quickstart-azure-ai-foundry
Try it yourself
Run this tutorial as a Jupyter notebook: Download runbook.ipynb (25 cells, 22 KB).



